Ein praktischer Leitfaden für Context Engineering
8 Min. Lesezeit•Thread von Jarrod Watts (@jarrodwatts) vom 23.1.2026•Tags: patterns/context-engineering, prompt-engineering, agents, productivity
Ursprünglich veröffentlicht von Jarrod Watts auf X.

"AI Slop" (minderwertiger KI-Output) ist nicht länger die Schuld des Modells, sondern die Schuld des Nutzers. In Black-Box-Systemen wie Claude Code ist der Kontext der einzige Input, den wir kontrollieren können – also wie optimieren wir ihn?
Was ist Kontext?
Kontext bezieht sich auf alles, was du einem LLM zur Verfügung stellst, wenn du ihm eine Nachricht sendest. Das beinhaltet:
- Den Prompt selbst
- Alle umgebenden Informationen (System Prompts, Metadaten)
- Deine vorherigen Nachrichten
- Das "Denken" (Thinking) des LLMs
- Tool-Calls und Antworten
LLMs haben begrenzte Context Windows – schlichtweg, weil es für sie schwieriger wird, den Überblick in der Konversation zu behalten, je größer diese wird.
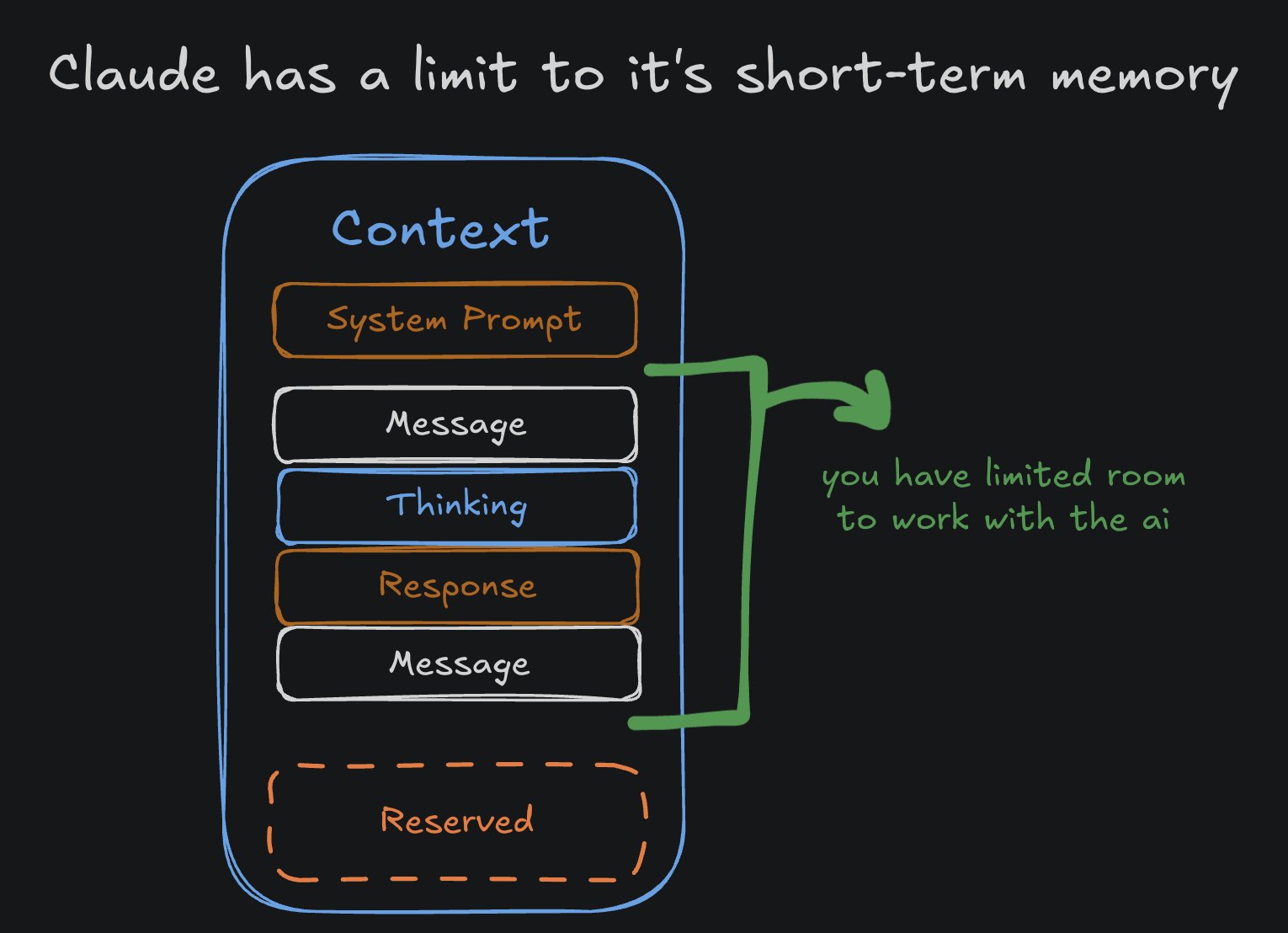
In Claude Code beträgt unser Context Window nur 200k Token. Das klingt vielleicht nach viel, füllt sich aber tatsächlich ziemlich schnell. Wenn wir /context ausführen, sehen wir warum:
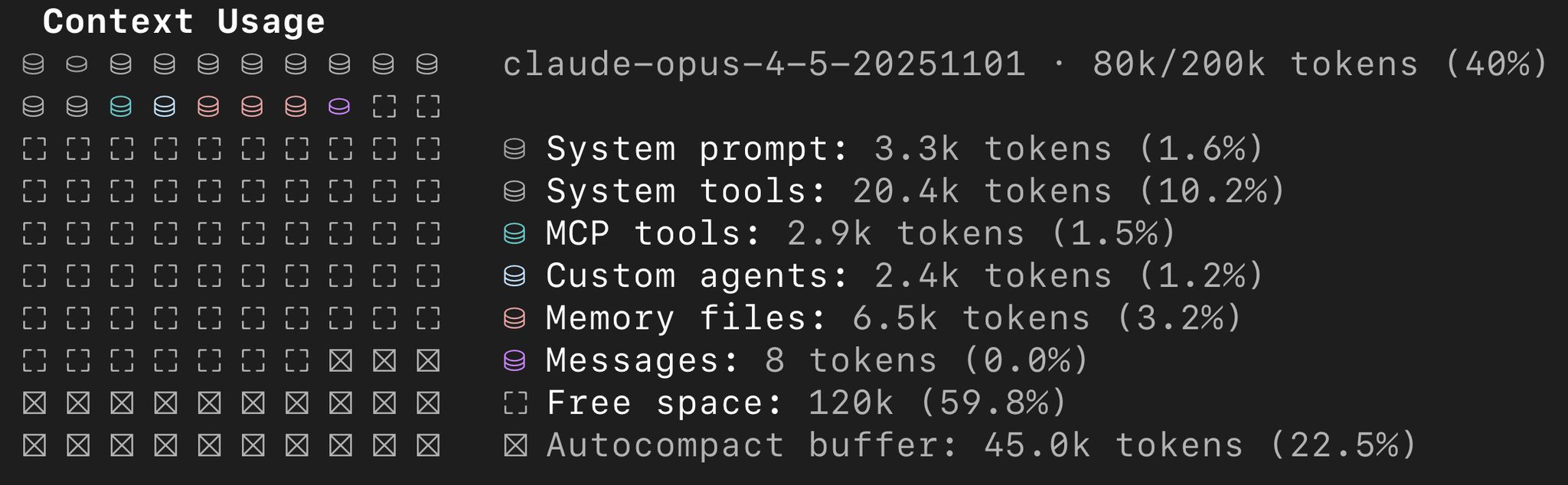
- 22.5% sind reserviert.
- ~10% werden von System Prompts eingenommen.
- Nach MCP-Servern, Sub-Agents und Rules bleibt nicht viel übrig.
Wir haben tatsächlich nur etwa 120k Token zur Verfügung. Und nicht nur das: Die Leistungsqualität des LLM nimmt ab, je mehr Kontext wir haben – unabhängig davon, ob wir uns dem Limit nähern oder nicht.
Was sollten wir also in unseren Kontext packen, um das "optimale Set an Token" zu erreichen und den Output zu maximieren?
Das Meiste ist nicht kompliziert (80/20 Regel)
Wie bei den meisten Dingen gilt auch beim "Vibe Coding" die 80/20-Regel. Du bist schon zu 80% am Ziel, wenn du Claude Code installiert und folgende Grundlagen erledigt hast:
/upgrade-> Max Plan (ja, den wirst du brauchen)/model-> Opus 4.5/init-> Erstelle eine Datei, die Claude hilft, dein Projekt-Setup zu verstehen.
Von hier aus ist der meiste generische Rat, den du wahrscheinlich schon gehört hast, korrekt:
- Starte im Plan Mode (
Shift + Tab). - Bitte Claude, Unklarheiten zu beseitigen, indem es dir Fragen zum Plan stellt.
- Führe den Plan aus, den du erstellt und verfeinert hast.
Sub-Agents, Custom Commands, Hooks und Multi-Agent-Orchestrierung machen Spaß, sind aber oft nicht so entscheidend, wie es scheint. Die Grundlagen richtig zu beherrschen, ist wichtiger.
Den Workflow richtig nutzen
Behandle jede neue Konversation als ein Ziel (Objective) und bleibe im Rahmen dieses Ziels. Zum Beispiel sollte jeder neue Thread ein Ziel haben wie:
- "Ich möchte diesen Bug fixen, den ich gerade habe."
- "Ich möchte dieses Feature der App bauen."
Bei neuen Projekten darf das Ziel breiter sein, aber das erfordert mehr Planung und Verfeinerung, da mehr Raum für Missverständnisse durch Ambiguität entsteht.
- Plane länger und verfeinere deinen Plan noch länger.
- Lass Claude dir Fragen stellen, bis keine Unklarheiten mehr bestehen.
- Bitte es, deinen Plan mehrfach zu reviewen (Architektur, Best Practices, Sicherheitsrisiken, Teststrategie).
- Ziel ist es, überall dort Details zu liefern, wo Unklarheit herrscht.
Wann du resetten solltest (und wie)
Wenn es gut läuft und du an ähnlichen Aufgaben weiterarbeiten willst: Mach weiter!
Wenn du dich dem Kontext-Limit näherst: Führe /compact aus, um Platz zu schaffen (oder lass Claude es automatisch tun – dafür ist der 22.5% Buffer da).
Aber was, wenn es nicht gut läuft? Das Modell hat nicht getan, was du wolltest, und du steckst in einem Loop aus "das ist furchtbar, bitte fixen" → Slop → "Junge, das ist noch schlimmer, was denkst du dir?" → Slop.

Wenn du hier bist: Spul zurück oder fang neu an.
Was du nicht tun solltest: Im Thread weitermachen und versuchen, es zu retten. Das ist es nicht wert. Stattdessen:
/rewind-> Geh zurück zu einem Punkt in der Konversation, wo es noch gut lief./new-> Starte einfach einen neuen Thread. Nimm deinen ursprünglichen Prompt, verfeinere ihn und versuche es erneut. Füge explizit hinzu, was nicht getan werden soll, basierend auf dem, was schiefgelaufen ist.
Die Komplexitätsfalle vermeiden
Wenn du auf X (Twitter) unterwegs bist, wirst du mit ausgefallenen Setups überflutet – MCP-Server, Sub-Agents, Skills.
Mein erster Rat: Verkompliziere die Dinge nicht übermäßig. Unser Ziel ist es, wie Anthropic sagt, das "kleinstmögliche Set an High-Signal Tokens" zu finden.
Je mehr du den Kontext mit Daten von MCP-Servern flutest, desto mehr füllst du dein Fenster mit "Low Signal" – und verbrennst dabei Geld.
MCP Server für guten Kontext nutzen
MCP Server sind im Grunde Third-Party-Tools, aus denen das LLM nützlichen Kontext beziehen kann (Docs, GitHub Code, Linear Tickets, Figma Designs etc.).
Viele davon fressen deinen Kontext auf und sind es oft nicht wert. Jarrod nutzt derzeit hauptsächlich drei:
exa.ai-> Web-Suche für AI Agentscontext7-> Aktuelle Docs für AI Agentsgrep.app-> GitHub-Suche für AI Agents
Nutze MCP-Server hauptsächlich, um Kontext zu sammeln, wie man Code richtig implementiert – eine "Just in Time" Context-Strategie.
Sub-Agents nutzen, um Kontext zu sparen
Claude Code kann Sub-Agents (andere Instanzen von Claude Code) als Kinder des Haupt-Agents erstellen. Du kannst deine Sub-Agents mit /agents sehen.
Das Wichtige an Sub-Agents:
- Sie haben ihr eigenes, separates Context Window.
- Sie können ein anderes Modell (z.B. Sonnet statt Opus) nutzen.
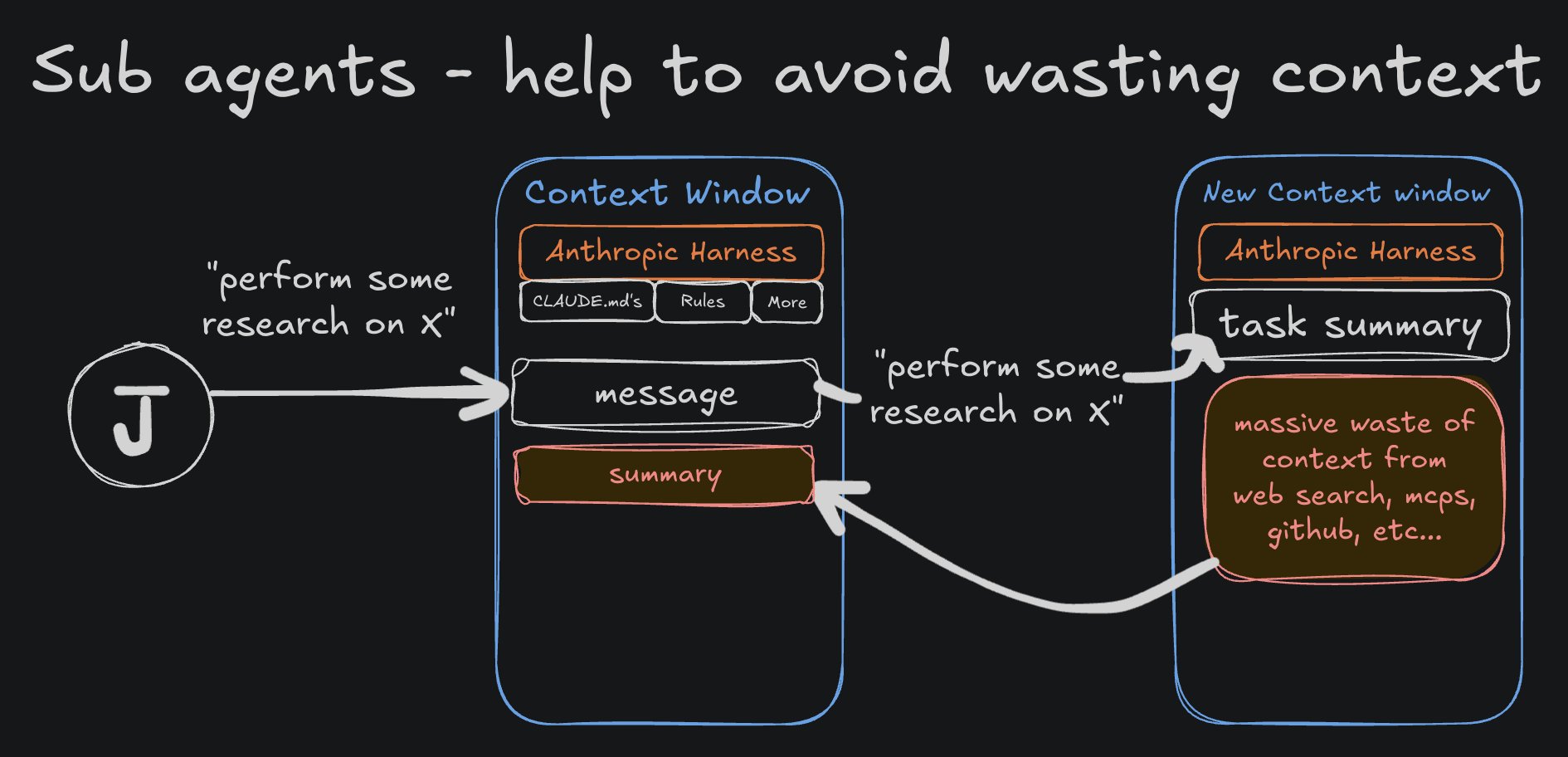
Das bedeutet, wir können Sub-Agents spawnen, die "teure" Operationen (wie Recherche) durchführen und dem Haupt-Agent nur eine Zusammenfassung liefern. Das spart Token im Hauptkontext.
Beispiel "Librarian" Workflow: Ein Custom Sub-Agent, der Sonnet nutzt, um Open Source Repos und Dokumentation zu scannen und eine Zusammenfassung an den Haupt-Agent liefert. Prompt an Haupt-Agent: "Nutze Librarian, um zu recherchieren, wie man X mit Library Y macht, und implementiere dann Z."
Skills nutzen, um relevanten Kontext reinzuholen
Skills sind quasi das Gegenteil von Sub-Agents. Statt Aufgaben an einen Agenten mit separatem Kontext zu delegieren, holst du spezialisiertes Wissen in den aktuellen Kontext.
Beispiel: Ein "Frontend Designer" Skill, der einen langen Prompt in den Kontext lädt, der Claude Do's & Don'ts für Frontend-Design erklärt.
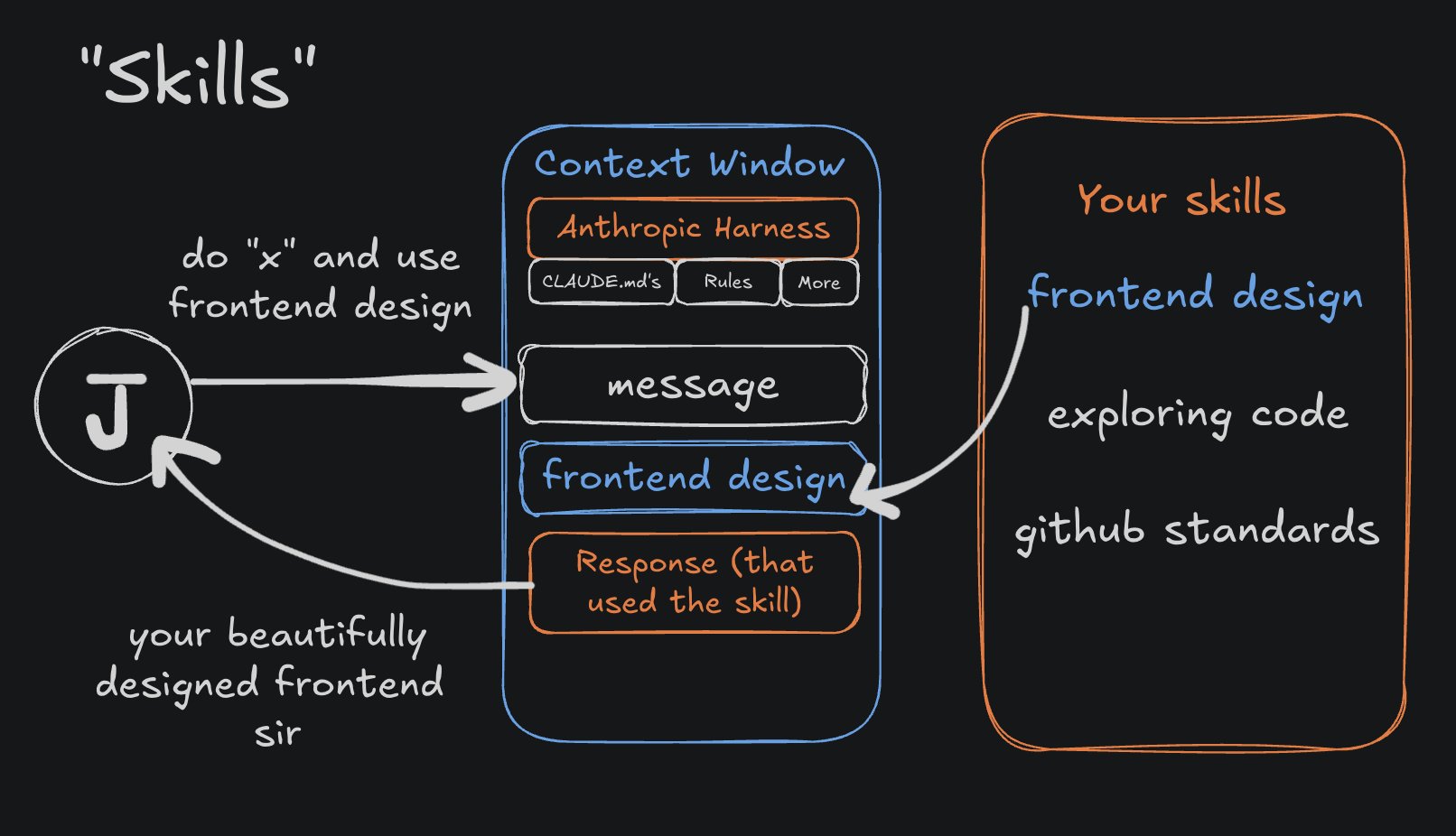
Das klingt fancy, ist aber einfach nur ein Textblock, der bei Bedarf in den Kontext geladen wird.
Takeaways
Gutes "Vibe Coding" bedeutet, auf wertdichten Kontext (Value-Dense Context) zu optimieren. Jede Information, die du hinzufügst oder vom LLM erhältst, sollte präzise darauf abzielen, dem LLM bei der Beantwortung der nächsten Anfrage zu helfen.
Wenn es das nicht tut – solltest du nicht im selben Kontext weitermachen. Das ist der Schlüssel, um die frustrierenden "Slop Traps" zu vermeiden.
Es ist nicht so kompliziert, wie es klingt. Versuch dein Bestes, dem LLM mit präzisen, qualitativen Informationen zu helfen und gib ihm Tools, um relevante Informationen selbst zu finden – genau wie du es bei einem Kollegen tun würdest.
Verbindungen
- [[Context Window]]
- [[Value-Dense Context]]
- [[MCP]]
- [[Subagents]]
- [[Skills]]
- [[Claude Code]]
- [[Opus 4.5]]
- [[/compact Command]]
- [[Plan Mode]]
- [[Context Engineering]]
- [[Vibe Coding]]
- [[Prompt Engineering]]